I’ve finally managed to combine my two main hobbies of data science and running into one project: a Shiny web-app that allows you to explore your Strava fitness data, as well as providing a local database of all your activities that you can analyse with R.
My initial motivation was that I wanted quick access to certain visualisations and metrics that either Strava doesn’t provide, or are awkward to get so I wrote a basic app for my own use. However, I then realised that there almost certainly would be others who would value from this work, either from the app itself or the infrastructure to create and maintain a local database of your Strava data, and I decided to open it up. I stuck with the local route of everyone installing (and customising!) their own Shiny app, rather than me hosting a central version in the Cloud as I strongly feel that everyone should have complete ownership of their own data.
TL;DR: Install from GitHub
App functionality
The app itself looks as below, with the main page providing a quick GitHub-style calendar showing activities in the last year, along with an interactive table of all activities, which I find far quicker to search for a specific activity than the Strava website.
NB: the ‘Activity Type’ checkbox on the left allows you choose which sports are shown for this page and all pages. By default this is set to Runs only but you can change in the settings (cog icon in the top right).
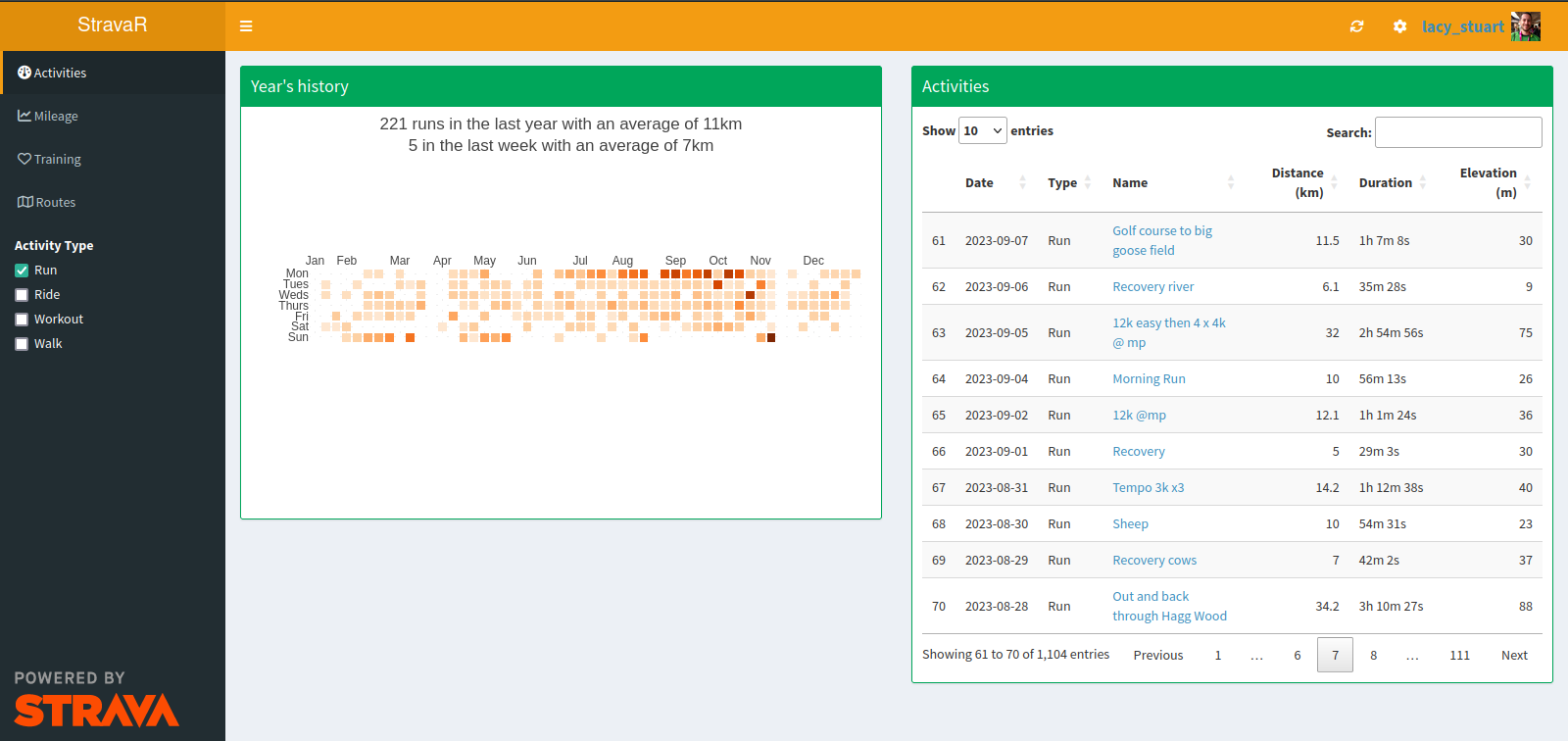
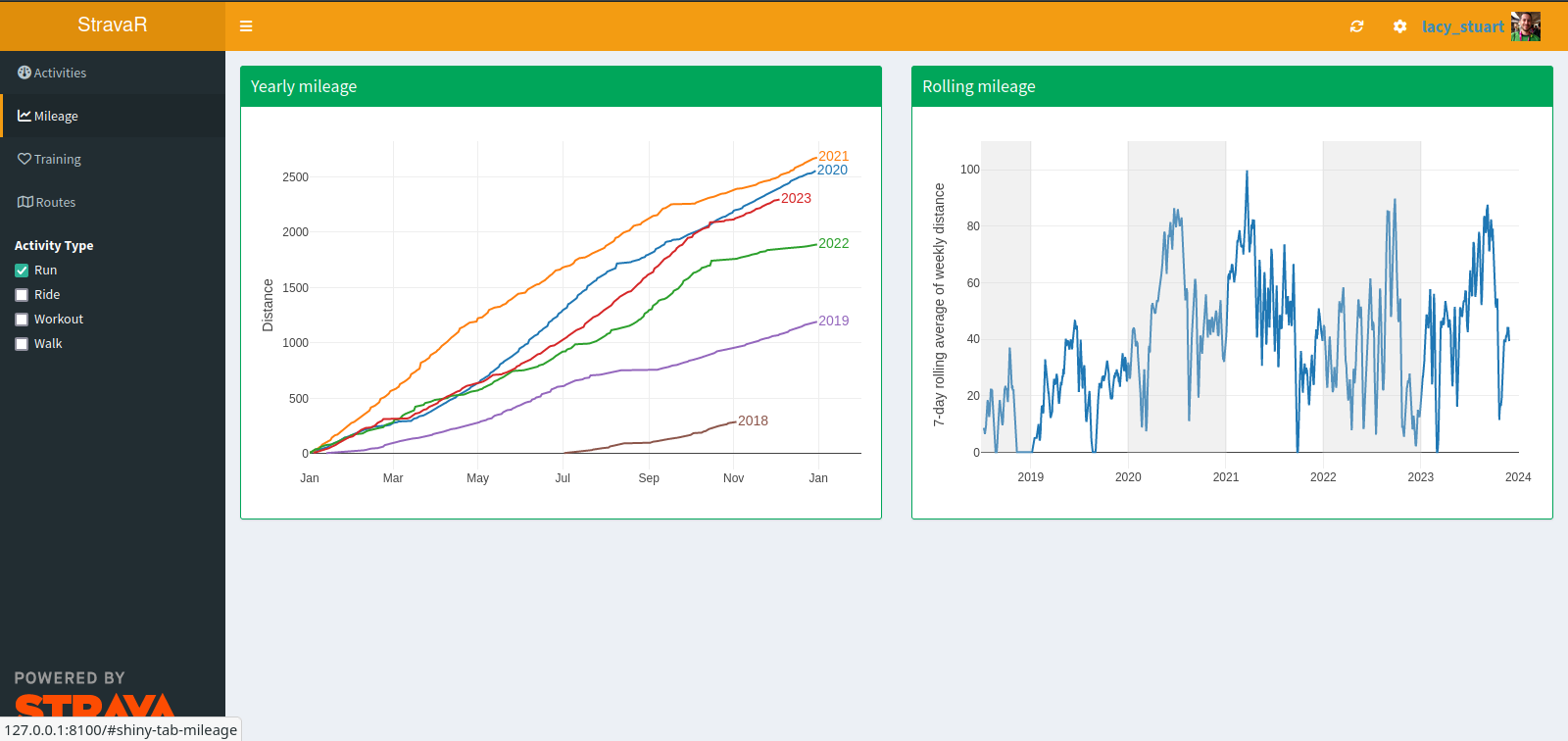
The main metric that guides my training programs is my mileage, so I want to be able to see at a glance both how my weekly mileage is doing, and also how my year-to-date cumulative load compares with previous years.
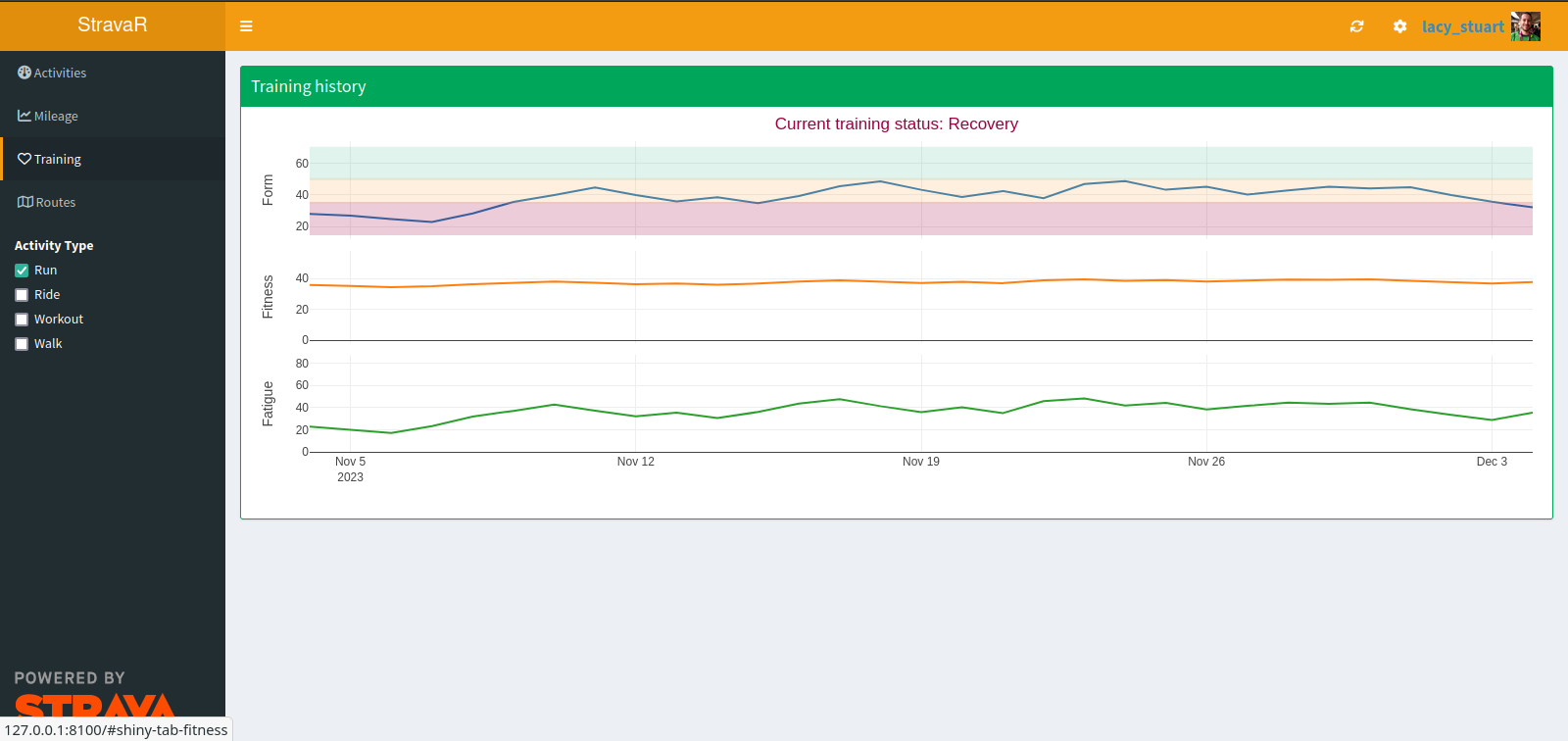
I like being aware of my heart-rate stress score based training load too, which is the same metric used in the Elevate extension.
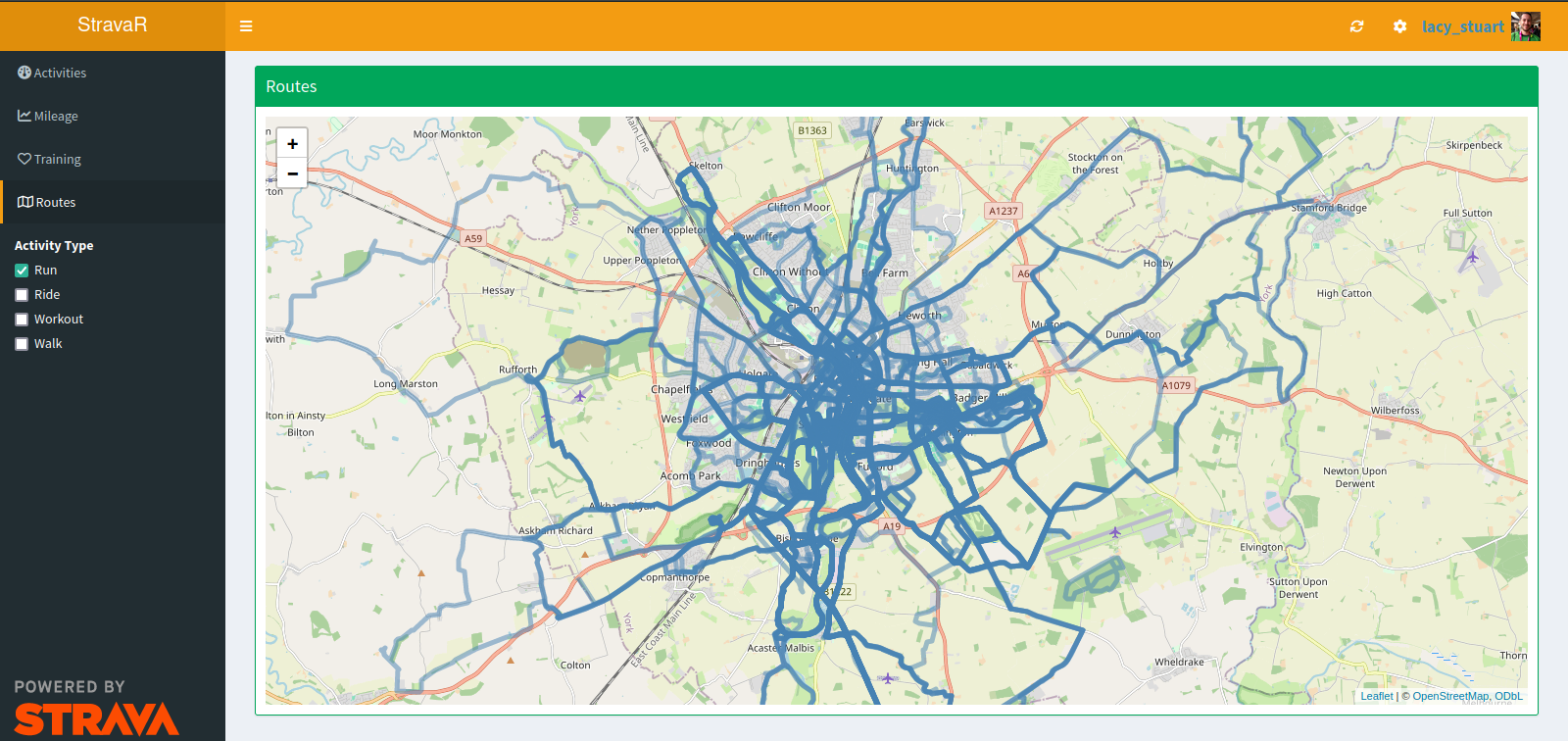
The final page displays an interactive map of all activities. When I’m not in a specific training cycle, my main motivation (especially during the winter!) comes from exploring new routes. One feature I’d like to add is the calculation of what percent of runs in a specified area you have run on, watch this space…
Uploading data
On first use, you will be prompted to upload an exported archive from Strava containing all your data. This can be downloaded from the (deliberately?) confusingly named page Delete Your Account (NB: this link WILL NOT delete your account!). If you don’t want to click that scary link, in a web browser click your Profile Pic in the top right, Settings, My Account, scroll down to Download or Delete Your Account and click Get Started. Your archive will be emailed to you shortly
Linking to Strava
For subsequent use you can either continue the tedious manual process of requesting archives, waiting for the email, and uploading it, or you can directly link your account to Strava through the API.
You’ll need to create an App through Strava’s developer scheme and substitute the Client ID and Secret in the line STRAVA_APP <- oauth_app(...) in server.R as the key and secret arguments respectively.
Then you are good to go by clicking the Connect With Strava button in the top right!
Why can’t I just use your key and secret?
Because the oauth 2.0 authentication method used by the Strava API isn’t ideal for Desktop Apps (as in those that get installed to each users’ computer, rather than running a single instance in the Cloud), as there’s no way of installing the app without making the key and secret accessible to the user.
These values are considered sensitive because anyone could use them to make you think you were authorising your Strava account to connect to my app, but in reality they get access to your data.
I didn’t want to write a Cloud based app as I’d rather everyone be able to own and manage their own data, rather than hand it off to yet another third party!
Database
The app creates a duckdb database to store your data, which is an embedded database designed for analytics (i.e. it is column-based compared to SQLite’s row-based), this saved in the working directory as data.db.
It supports querying through standard SQL commands, see the documentation, although it is much easier to interface to it using the fantastic dbplyr package which allows you to use standard tidyverse functions instead.
For example, to load all your activities you would do the following:
library(tidyverse)
library(duckdb)
# Connect to the database
con <- dbConnect(duckdb(), "data.db")
tbl(con, "activities") |>
collect() # This command reads the data from the DB into memory
# A tibble: 1,171 × 7
activity_id activity_type name start_time distance duration elevation
<dbl> <chr> <chr> <dttm> <dbl> <dbl> <dbl>
1 9329577757 Run "Stretching legs" 2023-06-25 06:43:26 7.5 2534 18.3
2 9337323631 Run "Cow cow cow" 2023-06-26 11:22:44 8.01 2667 42.9
3 9342310857 Run "Bish" 2023-06-27 06:58:44 8 2605 20.2
4 9355605801 Run "Acaster Malbis river" 2023-06-29 09:12:45 16 5516 17.0
5 9361568591 Run "Recovery" 2023-06-30 10:19:55 5.01 1830 29.7
6 9370223236 Run "Chill evening run" 2023-07-01 18:21:45 8.01 2615 15.5
7 9378957042 Run "Askham Richard - Bilbrough - Cop - Bog - Bish" 2023-07-03 06:06:38 23 8126 102.
8 9385907307 Run "Cows" 2023-07-04 11:12:57 6.3 2094 20.8
9 9392630511 Run "Golf course \"\"10\"\"" 2023-07-05 11:08:25 11.5 3790 29.3
10 9399049616 Run "Threshold run 5x1km" 2023-07-06 11:41:49 10.0 3119 16.8
# ℹ 1,161 more rows
# ℹ Use `print(n = ...)` to see more rows
You can use standard tidyverse functions on the database connection before you load it into R with collect, i.e. if I want to find all my long runs from Summer 2020 I could do the following:
tbl(con, "activities") |>
filter(
start_time >= '2020-05-01',
start_time < '2020-09-01',
distance > 20,
activity_type == 'Run'
) |>
arrange(desc(distance)) |>
collect()
# A tibble: 12 × 7
activity_id activity_type name start_time distance duration elevation
<dbl> <chr> <chr> <dttm> <dbl> <dbl> <dbl>
1 3887193271 Run Lockdown marathon 3:51:42 2020-08-09 07:16:46 42.3 13945 152.
2 3786050932 Run Too hot! 2020-07-19 11:08:24 34 12905 79.0
3 3578083277 Run Lunch Run 2020-06-07 10:50:03 32.2 12970 101.
4 3648703947 Run Morning Run 2020-06-21 09:41:21 32.2 12080 92.2
5 3717455954 Run Lunch Run 2020-07-05 10:51:51 32.2 11588 83.9
6 3751088445 Run Lunch Run 2020-07-12 10:38:14 27.5 9485 78.2
7 3542179455 Run Lunch Run 2020-05-31 11:27:01 27.5 9934 67.5
8 3683255248 Run Lunch Run 2020-06-28 10:15:23 24.2 7936 71.9
9 3467388733 Run Afternoon Run 2020-05-17 13:48:47 24.1 8420 47.5
10 3613589532 Run Half marathon pb 1:42:31 2020-06-14 11:39:48 21.1 6164 51.8
11 3820814279 Run Half marathon pb 1:39:53 2020-07-26 11:11:18 21.1 6074 51.4
12 3430728862 Run Afternoon Run 2020-05-10 13:59:18 21 7568 61.9
NB: When you are finished with the database, close the connection and shut it down!
dbDisconnect(con, shutdown=TRUE)
Installation
Simply clone the GitHub repository (from within RStudio, File -> New Project -> Version Control -> Git, then enter https://github.com/stulacy/StravaR.git as the Repository URL), then install any missing packages that are loaded in server.R (RStudio should highlight these).
You can then run the app in a web browser by opening app.R, clicking the arrow next to Run App and selecting Run External, and then clicking Run App.
On first use it will create the database, prompt you to enter details about yourself, and prompt for a Strava archive file.
Extending the app
Feel free to modify the source code to your heart’s content to meet your specific needs. If you come up with any interesting visualisations or models please let me know - I’d be interested to see what people get up to!