And so we come to the end of another season of football, and more importantly, Predictaball! This season has seen several large updates that I was meaning to detail these at the start of the season but life got in the way.
- The predictive model is now fully Bayesian
- I’ve added a betting system that identifies value bets
- I’ve expanded it to include the 3 other main European leagues:
- La liga
- Serie A
- Bundesliga
Rather than detailing these new aspects as well as summarising the season’s performance in one massive blog, I’ll split this into two parts. The first (this one) will summarise the Bayesian hierarchical model that I use for predicting match outcomes and its accuracy over the course of the season. The second part will discuss the betting scheme I implemented and how rich that made me (spoilers, not very much).
Bayesian hierarchical model
Over last summer I upgraded the Naive Bayes classifier to a fully
Bayesian hierarchical model, using the fantastic rjags R package to
interface with JAGS. It assumes the match outcome $O$ is distributed as
a multinomial (JAGS prefers the term categorical distribution as the
multi-variate generalisation of the Bernouilli trial, i.e. the
Multinomial where $n = 1$).
$$O_{i} \sim Multinomial(1, \phi_{i})$$ $$log(\phi_{ik}) = \alpha_{league_{i}k} + \gamma_{1k}\eta_{home_{i}} + \gamma_{2k}\eta_{away_{i}} + \sum_{j}^{4}{\beta_{j} X_{ij}}$$
For $k \in {1, 2, 3}$ representing the W/D/L outcomes of a match.
Where:
- $\alpha$ is the league and outcome dependent intercept
- $\eta$ is a team-level intercept that provides a measure of team strength
- $X$ are 4 match-level predictors that measure the current form each
team is in, using metrics collected over the last 5 matches:
- # of wins for the home team
- # of losses for the home team
- # of wins for the away team
- # of losses for the away team
There are three levels in this model: league, team, and match. It is a random intercepts model, since there are league and team dependent intercepts, with the slopes on a match level. I’m not going to provide exact implementation details (although can provide them on request), but I used vague priors and the last 11 seasons worth of data to fit the model. Convergence took around 10 hours on my rather basic home server.
Match Prediction Accuracy
Overall
There have been 1176 matches this season across all 4 leagues with 678 (58%) of these outcomes being correctly predicted. This is a better accuracy than expected, since this classifier only got 50% on the 2015-2016 season that I was using as my test set.
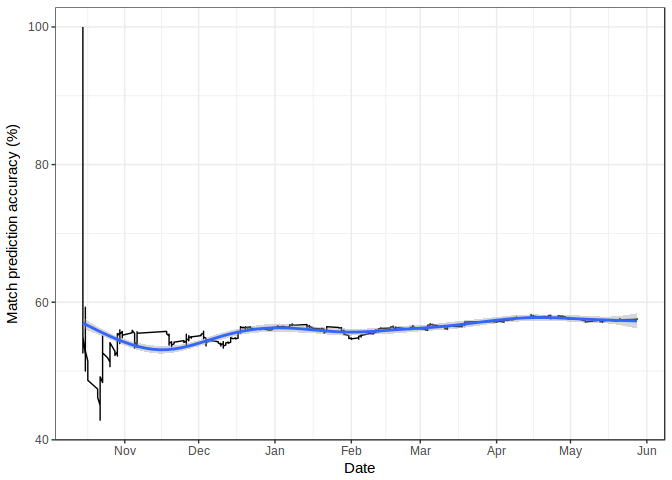
The figure below plots the overall accuracy across the season, highlighting that there is a period of uncertainty at the start of the season where teams adapt to their new squads, managers, and competition, before settling down into a steady state around Christmas. It’s important to note that I didn’t start Predictaball running until October this year. This is mostly due to needing to wait until 5 games have been completed to obtain form data.
Stratified by league
On its own, an accuracy of 58% is rather promising, but more information about the model performance can be gained from looking at each league in isolation.
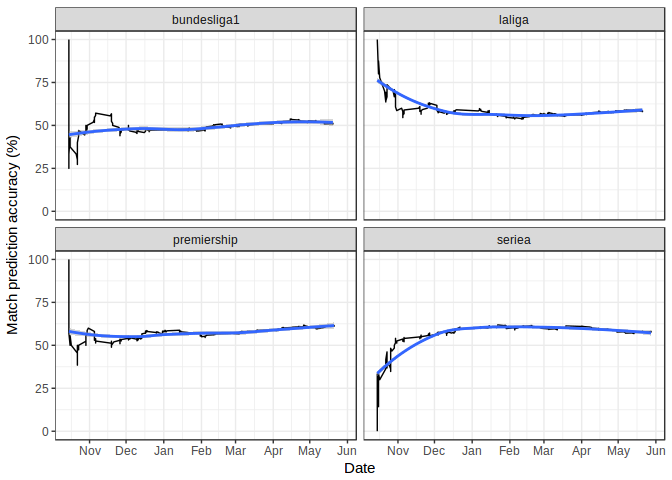
The table below shows the match accuracy split by league, and suggests that there is a significant difference in each league’s predictability, since the English, Spanish, and Italian leagues all have accuracies around 58-60%, but the Bundesliga trails far behind on 51%. This is unexpected, particularly since the prediction model accounts for inter-league variance by having league-dependent intercepts.
One factor that could go some way to explaining this behaviour is RB Leipzig, who were newly promoted to the Bundesliga this season but played very well (not too unexpectedly given their recent takeover) and came second. Because they hadn’t played in the Bundesliga before they were not included in the training data and therefore were not provided with a strength distribution. Instead, for each match prediction they were assigned a random sample from the mean team strength posterior for the German teams. However, as was quickly apparent, they were far stronger than an average team and so Predictaball continuously underestimated their chances.
| League | Accuracy |
|---|---|
| premiership | 62 |
| laliga | 58 |
| seriea | 58 |
| bundesliga1 | 51 |
The high accuracy on the Premier League (62%) looks very promising for the fully Bayesian approach. This is a massive improvement on the previous two seasons of 43% (Naive Bayes) and 48% (Evolutionary Algorithm classifier), indicating that either the league was more considerably more predictable this season or that the Bayesian framework is more adapt at identifying trends in the data. I imagine it’s a combination of both factors. The particularly poor performance last season can be explained by the rather chaotic season with Leiester winning and the reigning champions Chelsea havng a nightmare start, however, this doesn’t explain the 14% difference between the current season and 2014-2015, and so the Bayesian model deserves some of the credit.
The plot below displays accuracy as a function of time, split by league. As shown before, it takes until around Christmas for the accuracy to steady. I believe this behaviour is simply due to there being more upsets at the start of the season as teams are adjusting to their new squad and management, before settling into a rhythm around Christmas. I can’t imagine it’s due to the model structure since the only time-varying part of the model are the form factors for W/D/L in the last 5 games, It would be useful if I could model this initial behaviour better however…
Next time I’ll discuss the betting scheme as well as planning future improvements to Predictaball.