I’ve always been curious to know if any of the 4 major European leagues (Serie A, Bundesliga, Premiership, La Liga) are more predictable than others. La Liga certainly has a reputation as being dull and predictable, although this is due to the sheer dominance of Barcelona and Real Madrid in recent years. I’ve increased my database of football matches in order to improve my football prediction bot this summer, and so now have sufficient data to investigate. In this analysis my measure of predictability is whether the favourite according to the bookies won the match, so in essence I’m measuring the number of upsets. I have access to a data set comprising full match results from the last 11 seasons (2004⁄2005 through to 2015⁄2016) for the four major European leagues, along with the prior odds assigned to each of the three possible match outcomes. Note that the particular bookies I’m using is William Hill, and so in theory there could be an element of bias here as this is an English bookmakers, who presumably would have additional expertise in the English football leagues since this will be by far their biggest market. In the modern globalised world this could be completely wrong as they could contract out markets in different countries to local bookmakers, or form their odds by analysing the market - I have no idea, but just worth bearing in mind.
Initial look
I’ll be running my analysis in R, so I need to load some libraries as well as load my data (not shown).
library(dplyr)
library(ggplot2)
library(ggthemes)
Let’s have a quick look at the raw data (already collated in a variable
called res) to check it looks sensible first:
knitr::kable(head(res))
| id | league | season | homeodds | drawodds | awayodds | outcome |
|---|---|---|---|---|---|---|
| 1 | premiership | 2012-2013 | 0.5780347 | 0.2777778 | 0.2083333 | h |
| 2 | premiership | 2012-2013 | 0.8000000 | 0.1818182 | 0.0833333 | h |
| 3 | premiership | 2012-2013 | 0.7518797 | 0.2000000 | 0.1111111 | a |
| 4 | premiership | 2012-2013 | 0.1818182 | 0.2309469 | 0.6535948 | a |
| 5 | premiership | 2012-2013 | 0.5555556 | 0.3076923 | 0.2000000 | d |
| 6 | premiership | 2012-2013 | 0.5555556 | 0.2777778 | 0.2309469 | a |
summary(res)
## id league season homeodds
## Min. : 1 bundesliga1:3366 2005-2006:1446 Min. :0.03846
## 1st Qu.: 3882 laliga :3800 2006-2007:1446 1st Qu.:0.37037
## Median : 8144 premiership:4180 2008-2009:1446 Median :0.47619
## Mean : 8198 seriea :4180 2009-2010:1446 Mean :0.48377
## 3rd Qu.:12405 2010-2011:1446 3rd Qu.:0.59880
## Max. :16286 2011-2012:1446 Max. :0.98039
## (Other) :6850
## drawodds awayodds outcome
## Min. :0.05882 Min. :0.01961 a:4358
## 1st Qu.:0.27778 1st Qu.:0.20000 d:3955
## Median :0.30303 Median :0.29412 h:7213
## Mean :0.28945 Mean :0.31188
## 3rd Qu.:0.32258 3rd Qu.:0.38462
## Max. :0.98039 Max. :0.92593
##
I now need to make a new column indicating whether the
bookies got the prediction right or not, stored as an integer. This will
be my dependent variable for much of the subsequent analysis, with the
league factor being my principal independent variable of interest. I’m
also curious to see how this predictability varies with time, and so
I’ve included the season for each match under the season predictor.
res_clean <- res %>%
group_by(id) %>%
mutate(predicted = c('h', 'd', 'a')[which.max(c(homeodds, drawodds, awayodds))],
correct = as.numeric(predicted==outcome))
Perfect, the data is in a format suitable for analysis.
knitr::kable(head(res_clean))
| id | league | season | homeodds | drawodds | awayodds | outcome | predicted | correct |
|---|---|---|---|---|---|---|---|---|
| 1 | premiership | 2012-2013 | 0.5780347 | 0.2777778 | 0.2083333 | h | h | 1 |
| 2 | premiership | 2012-2013 | 0.8000000 | 0.1818182 | 0.0833333 | h | h | 1 |
| 3 | premiership | 2012-2013 | 0.7518797 | 0.2000000 | 0.1111111 | a | h | 0 |
| 4 | premiership | 2012-2013 | 0.1818182 | 0.2309469 | 0.6535948 | a | a | 1 |
| 5 | premiership | 2012-2013 | 0.5555556 | 0.3076923 | 0.2000000 | d | h | 0 |
| 6 | premiership | 2012-2013 | 0.5555556 | 0.2777778 | 0.2309469 | a | h | 0 |
Exploratory Analysis
Let’s do some quick summary statistics then. Firstly we can see the overall % of matches correctly predicted by the bookies:
mean(res_clean$correct)
## [1] 0.5314311
This is lower than I’d expected, considering that in the last two seasons Predictaball has got 48% and 43% I expected the bookies to be more accurate. It goes to show that football prediction is extremely challenging even for the professionals, although it is important to bear in mind that a bookies objective isn’t to maximise prediction accuracy, but rather profits by offering worse value odds (from a customer’s perspective).
We can break this down year on year, pooling together all the four leagues:
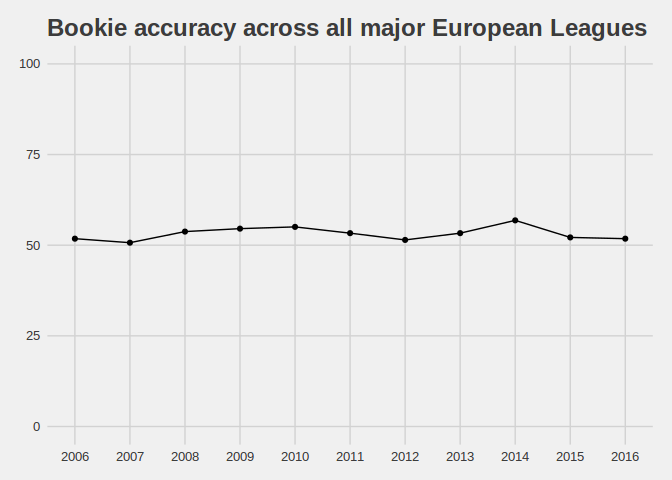
Across Europe there doesn’t appear to be any longitudinal shifts in bookie accuracy, I imagine that the league itself is a source of greater variation.
And what about accuracy by division?
res_clean %>%
group_by(league) %>%
summarise(accuracy = mean(correct) * 100) %>%
arrange(-accuracy) %>%
knitr::kable()
| league | accuracy |
|---|---|
| laliga | 54.3 |
| premiership | 53.9 |
| seriea | 53.1 |
| bundesliga1 | 51.0 |
Interestingly there doesn’t seem to be much difference between every league except the Bundesliga which is noticeably less accurate. People often deride La Liga for being too predictable, and while the main league outcomers tend to be one of 3 teams, the individual matches themselves look as tough to predict as those from any other league, with only a very slightly higher number of upsets (occasions where the favourite didn’t win).
Finally, we can look at accuracy by league and season, to see if there are any interesting patterns evident here which were masked when pooling the leagues together.
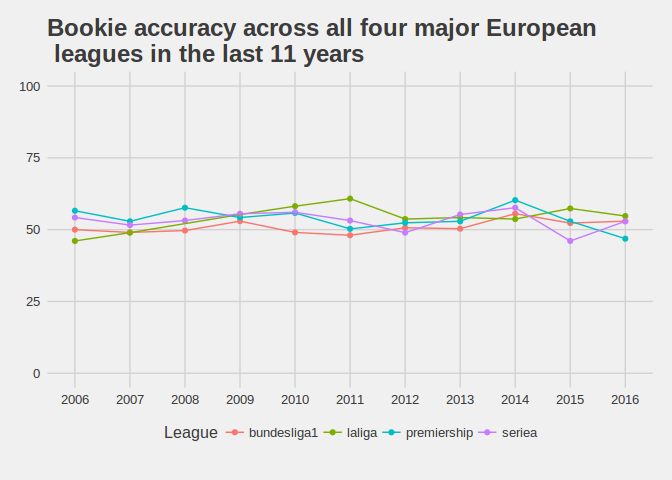
There are some interesting trends here, for instance the Premiership and Bundesliga follow a similar trend, with the Premiership having larger accuracies. The bookie’s accuracy in La Liga followed a very linear trend from 2005⁄2006 season culminating in the 2010⁄2011 season, before returning to similar levels as the other three leagues. Overall however, there does not appear to be a significant temporal aspect to the predictability of the leagues, with the league itself seemingly playing a more important role in the bookies’ accuracy than any time related factor.
Inference
From the earlier work we’re left with the impression of a subtle, but not large, effect of league on number of upsets (measured by whether the bookies’ favourite won), with seemingly little temporal element. Now let’s investigate these factors in more depth.
Chi-square
I’ll firstly run a $\chi^{2}$ test to see if there’s a statistically significant difference in the number of correct predictions by league, with the null hypothesis being that the proportion of upsets in each league is equal.
chisq.test(table(res_clean$correct, res_clean$league))
##
## Pearson's Chi-squared test
##
## data: table(res_clean$correct, res_clean$league)
## X-squared = 9.4037, df = 3, p-value = 0.02438
There does appear to be a statistically significant difference in proportion of upsets across the European leagues, even if it isn’t overly large in magnitude.
We can also investigate for a linear trend in seasons, using
prop.trend.test to account for the fact that the independent variable
is ordinal:
season_tabulated <- res_clean %>%
group_by(season) %>%
summarise(num_correct = sum(correct),
num = length(correct),
num_wrong = num - num_correct)
prop.trend.test(season_tabulated$num_correct, season_tabulated$num)
##
## Chi-squared Test for Trend in Proportions
##
## data: season_tabulated$num_correct out of season_tabulated$num ,
## using scores: 1 2 3 4 5 6 7 8 9 10 11
## X-squared = 0.48574, df = 1, p-value = 0.4858
Here we don’t have sufficient evidence to reject the null hypothesis that there’s a linear trend which supports my initial conclusions from inspection of the time-series.
Logistic regression modelling
Another way of investigating these two factors is in a logistic regression model, since the outcome is the proportion of favourites which won (the complement of number of upsets) which can be modelled using a binomial distribution.
Firstly I’ll create the null model for comparison later on. Quite a high deviance, indicating the model isn’t fitting too well.
mod_null <- glm(as.factor(correct) ~ 1, data=res_clean, family='binomial')
summary(mod_null)
##
## Call:
## glm(formula = as.factor(correct) ~ 1, family = "binomial", data = res_clean)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.231 -1.231 1.124 1.124 1.124
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.12589 0.01608 7.828 4.97e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 21462 on 15525 degrees of freedom
## Residual deviance: 21462 on 15525 degrees of freedom
## AIC: 21464
##
## Number of Fisher Scoring iterations: 3
Adding the league predictor only reduces the deviance by 10 (ignore
the AIC for now), with the coefficients for each league showing that
each league has a non-zero impact upon the predictability. Since the
baseline group here is the Bundesliga, the positive magnitude of the
betas shows that all three of the remaining leagues are more
predictable, with La Liga being the most.
mod_league <- glm(as.factor(correct) ~ league, data=res_clean, family='binomial')
summary(mod_league)
##
## Call:
## glm(formula = as.factor(correct) ~ league, family = "binomial",
## data = res_clean)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.251 -1.231 1.105 1.125 1.161
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.03803 0.03448 1.103 0.27000
## leaguelaliga 0.13397 0.04743 2.825 0.00473 **
## leaguepremiership 0.11730 0.04638 2.529 0.01144 *
## leagueseriea 0.08749 0.04636 1.887 0.05915 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 21462 on 15525 degrees of freedom
## Residual deviance: 21453 on 15522 degrees of freedom
## AIC: 21461
##
## Number of Fisher Scoring iterations: 3
A univariate model of the season predictor decreases the deviance
further as expected due to having more dummy predictors (and therefore
fewer degrees of freedom) than league. None of the individual seasons
have statistically significant effects, aside from 2013-2014.
mod_season <- glm(as.factor(correct) ~ season, data=res_clean, family='binomial')
summary(mod_season)
##
## Call:
## glm(formula = as.factor(correct) ~ season, family = "binomial",
## data = res_clean)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.296 -1.214 1.063 1.121 1.166
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 7.195e-02 5.263e-02 1.367 0.17157
## season2006-2007 -4.429e-02 7.441e-02 -0.595 0.55170
## season2007-2008 7.842e-02 8.089e-02 0.969 0.33230
## season2008-2009 1.111e-01 7.456e-02 1.490 0.13611
## season2009-2010 1.307e-01 7.460e-02 1.752 0.07982 .
## season2010-2011 6.102e-02 7.449e-02 0.819 0.41265
## season2011-2012 -1.385e-02 7.442e-02 -0.186 0.85241
## season2012-2013 6.102e-02 7.449e-02 0.819 0.41265
## season2013-2014 2.036e-01 7.476e-02 2.724 0.00645 **
## season2014-2015 1.385e-02 7.444e-02 0.186 0.85237
## season2015-2016 7.767e-16 7.443e-02 0.000 1.00000
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 21462 on 15525 degrees of freedom
## Residual deviance: 21443 on 15515 degrees of freedom
## AIC: 21465
##
## Number of Fisher Scoring iterations: 3
The next step is to add both the league and season into a combined model, as shown below. This model again increases deviance as expected, but not by a large amount. Of the predictors, the dummy variables representing belonging to each league are statistically significant, while only one of the seasons is, reinforcing previous findings.
mod_seasonleague <- glm(as.factor(correct) ~ season + league, data=res_clean, family='binomial')
summary(mod_seasonleague)
##
## Call:
## glm(formula = as.factor(correct) ~ season + league, family = "binomial",
## data = res_clean)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.318 -1.226 1.064 1.130 1.204
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.818e-02 6.098e-02 -0.298 0.76556
## season2006-2007 -4.432e-02 7.443e-02 -0.595 0.55157
## season2007-2008 9.555e-02 8.153e-02 1.172 0.24120
## season2008-2009 1.112e-01 7.458e-02 1.491 0.13598
## season2009-2010 1.308e-01 7.462e-02 1.752 0.07972 .
## season2010-2011 6.106e-02 7.451e-02 0.819 0.41251
## season2011-2012 -1.385e-02 7.444e-02 -0.186 0.85236
## season2012-2013 6.106e-02 7.451e-02 0.819 0.41251
## season2013-2014 2.038e-01 7.478e-02 2.725 0.00643 **
## season2014-2015 1.386e-02 7.446e-02 0.186 0.85232
## season2015-2016 -3.274e-16 7.445e-02 0.000 1.00000
## leaguelaliga 1.381e-01 4.782e-02 2.888 0.00388 **
## leaguepremiership 1.174e-01 4.641e-02 2.531 0.01139 *
## leagueseriea 8.760e-02 4.639e-02 1.888 0.05899 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 21462 on 15525 degrees of freedom
## Residual deviance: 21433 on 15512 degrees of freedom
## AIC: 21461
##
## Number of Fisher Scoring iterations: 3
We can also compare the models by AIC, which again reaffirms the belief that the league itself plays a far greater role in the number of upsets than the season.
data.frame(model=c('null', 'league', 'season', 'season+league'), aic=c(mod_null$aic, mod_league$aic, mod_season$aic, mod_seasonleague$aic)) %>%
arrange(aic) %>%
knitr::kable()
| model | aic |
|---|---|
| league | 21460.82 |
| season+league | 21461.22 |
| null | 21464.21 |
| season | 21464.91 |
Overall conclusions
The findings support the hypothesis that La Liga contains the fewest upsets out of the four major European football leagues, although the actual magnitude of the difference isn’t that large. Perhaps more interesting, is why the Bundesliga contains noticeably fewer upsets than the other leagues. An longitudinal effect has also been investigated but can be safely ignored.
When I come to forming predictive models of football leagues outside of the Premiership I’ll want to bear these subtle differences in mind, most likely by using a multi-level model to account for the fundamental hierarchical nature. If I decide to go down the Bayesian route this will be a simple addition, whereby the league can be modelled as a random effect.