It’s been a while since I’ve posted anything as I’ve spent my summer in a thesis related haze, which I’m starting to come out of now so expect more frequent updates - particularly as I work my way through the backlog of ideas I’ve been meaning to write about.
I’ll start with assessing Predictaball’s performance last season. Just to summarise, this was a classification task attempting to predict the outcome (W/L/D) of every premier league match from the end of September onwards. This was based on each team’s form across the last 5 matches, in terms of the number of wins, draws, and losses. The classification model was an ensemble evolved using an Evolutionary Algorithm approach that I developed during my PhD.
Predictions were tweeted each week, along with a summary of the previous week’s performance. However there were a few teething issues, such as having to manually update the fixtures database when these were modified, as I wasn’t aware that fixtures could be changed midway through a season. If I didn’t update the database in time then the classifier wasn’t able to predict those matches, which occurred every now and then, particularly during a 3 week stretch when I was away at a conference.
The aim of Predictaball was two-fold: 1. Apply an academic classification algorithm to a real world dataset 2. Establish whether it’s possible to produce human competitive predictive models.
To assess the extent to which I’ve met goal two, I’ll compare Predictaball’s accuracy to that from two professional pundits - Mark ‘Lawro’ Lawrenson and Paul Merson.
Predictaball Accuracy
Since Predictaball predicts based on the previous 5 matches, I’ve collated the results of Predictaball across the remaining 33 weeks of the season to total 330 matches. The total accuracy over this period is 48%. This value isn’t too bad for a classifier passed very little data, however I am confident I can improve upon this score this season by 2 ways: 1. Incorporating more data to explain the outcomes, such as whether key players are injured, record against the specific team, and so on 2. Using a more thorough model selection process, with a wider sweep of learning algorithms and associated hyper parameters
Out of these I expect #1 to result in by far the most significant improvement in accuracy, the primary challenge with machine learning is manipulating the data in such a way to explain the relationship best, rather than tweaking the specific choice of learning algorithm.
Similarly to how optimising your algorithms and data structures can provide far more significants speed ups than achieved by converting all your code to a lower level language, it’s better to ensure you have the best data available when modeling.
I’m curious to see whether Predictaball got more accurate over the course of the season, as teams settled into their average form. The figure below plots accuracy against time.
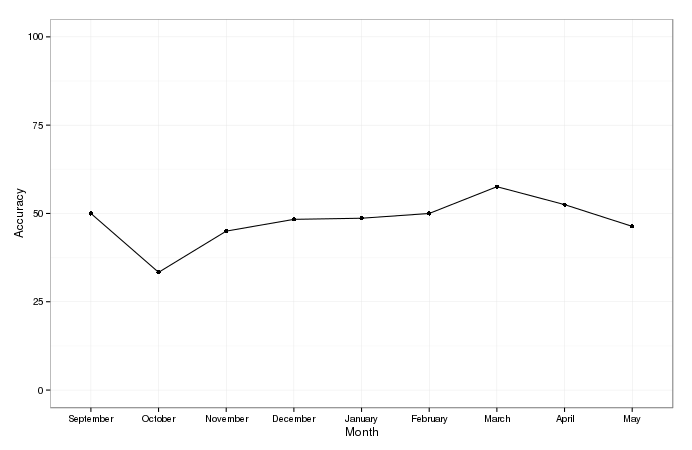
There’s a clear upwards trend until March, indicating that yes, matches do become more predictaball once new signings settle in and teams adjust to the new level of competition. After March however, the accuracy starts to drop off. This could be indicative of teams which are safe and not pushing for Europe taking their foot off the gas. In addition, owing to the afore-mentioned issues with the changing fixtures, I’ve got fewer data points from April and May and so these monthly averages are more subject to variance.
Human Competitiveness
To provide an estimate of how useful Predictaball is, I’ve compared its results to those from professional ex-footballer pundits, Lawro and Paul Merson, selected for their prominence as pundits. I couldn’t find predictions from Paul Merson for 8 midweek games, and so have removed these from the overall comparison resulting in 322 matches which I have predictions and the actual results for all 3 pundits. The results are show below.
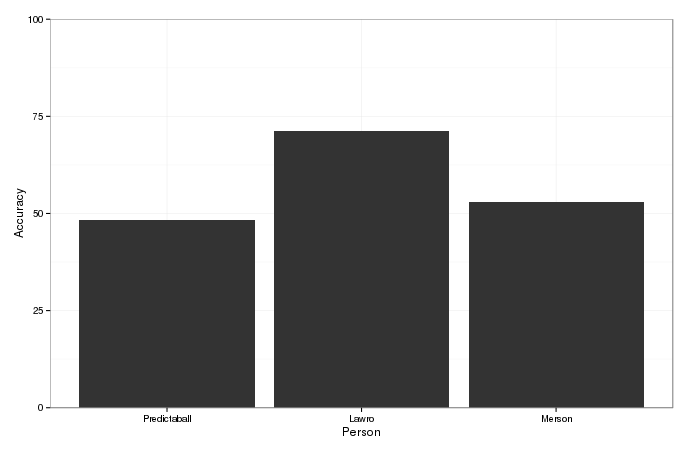
Amazingly, Lawro recorded an accuracy of 72%, far surpassing both Predictaball and Merson. This is an incredibly high accuracy, far more than I’ve seen before both in my automated training methods and also informally from other experts. It’s frustrating that I’m unable to beat Lawro as well, however the difference is relatively small and I’m confident I can beat him this year provided he doesn’t drastically improve his score.
Future work
My aim for next season then is to achieve an accuracy of ~55%, or to beat Merson at the very least. Approaching this from an algorithmic perspective would involve tweaking a boosting algorithm to squeeze every inch of value from each variable, however I believe the most predictive power to lie in the choice of data variables themselves rather than the classification model. To this end I’m going to try experimenting with different predictors until I find a set which best captures the underlying relationship.
Similarly to providing more explanatory factors, I’ll try modeling the temporal element of the football season to provide an additional dimension to the model. This would be achieved by using recurrent networks, the specific architecture is TBC.
However I am aware that the intrinsic noise component of the error from classifying football matches is very large, and so the optimal classifier would be far from 100% accurate.
Another issue this season was caused by fixtures changing; I naively assumed that the fixtures listed at the start of the season would stay the same the full way through. This year I’ll take that into account to build a more robust system which automatically searches for changes to the schedule.
I’ll also implement a thorough nested cross-validation system for both model selection and model evaluation, so that I can simply compare between candidate classifiers and obtain an estimate of their predictive power.