I’m a data scientist interested in applying machine learning to some of the biggest challenges facing society.
In my current role I work on high resolution air quality measurements recorded from low-cost sensors using a combination of deep learning and Bayesian statistics.
Previously I have applied machine learning to form complex survival models of haematological malignancies and analysed movement disorder data from neurodegenerative conditions.
I also have an interest in software development, and in particular developing tools for others to use, such as statistical packages in R and interactive dashboards.
My main tools are R, probabilistic machine learning in Stan, and PyTorch.
Motivation I recently needed to implement some time-series clustering at work on a high-dimensional dataset. Having not tackled this specific problem before, I wanted to practice on a smaller, univariate dataset where I already had a strong intuition about the underlying structure.
I turned to my exported Strava running data as a testbed to get familiar with clustering using Dynamic Time Warping (DTW).
Heartrate data Show the code library(tidyverse) library(duckdb) library(plotly) library(dtw) library(parallel) library(tidytext) library(ggwordcloud) library(patchwork) library(dendextend) library(ggridges) library(broom) library(cluster) I started by pulling data from my existing database, restricting the scope to runs that contain both heart rate and GPS location data.
Introduction And so finally we come to the end of this comparison of four different modelling strategies for predicting football matches: hierarchical Bayesian regression models, a traditional Elo rating system, an optimised Elo system using Evolutionary Algorithms (EAs), and online Bayesian models using Particle Filters. I’ll skip most of the code so we can jump straight to the results, but it’s all available by clicking on the folds in the following section.
Introduction This is the fourth in a series of posts looking back at the various statistical and machine learning models that have been used to predict football match outcomes as part of Predictaball. Here’s a quick summary of the first 3 parts:
Part 1 used a Bayesian hierarchical regression to model a team’s latent skill, where skill was constant over time Part 2 used an Elo rating system to handle time, but the functions and parameters were hardcoded and a match prediction model was bolted on top to replace Elo’s basic prediction Part 3 used Evolutionary Algorithms (EA) to simultaneously optimize the rating system and match prediction model without requiring any hardcoding parameters The EA model has working reliably for the last 5 and a half seasons and hasn’t been tweaked since.
Introduction The Elo models introduced last time, which were the models used on Predictaball from 2017-2019, worked very well but with some limitations. Firstly, the parameters used in the rating update equation (home advantage and margin of victory multiplier) were chosen manually by inspection for each league. If I wanted to apply Predictaball to a whole new set of leagues (yet alone sports!) I’d need to go through each one to identify new parameters - hardly ideal!
Introduction Following on from Part 1 in this series of posts looking back at the history of Predictaball, I’ll be reexamining the Elo models that were used from 2017-2019. One obvious flaw with the hierarchical Bayesian regression model was that there was no acknowledgement of time - a team’s skill was modelled at the point of training and kept fixed from them on. The model could be retrained after each match, but MCMC is time-consuming, and the resultant skill would still be an average over the full training period rather than the value at the current time.
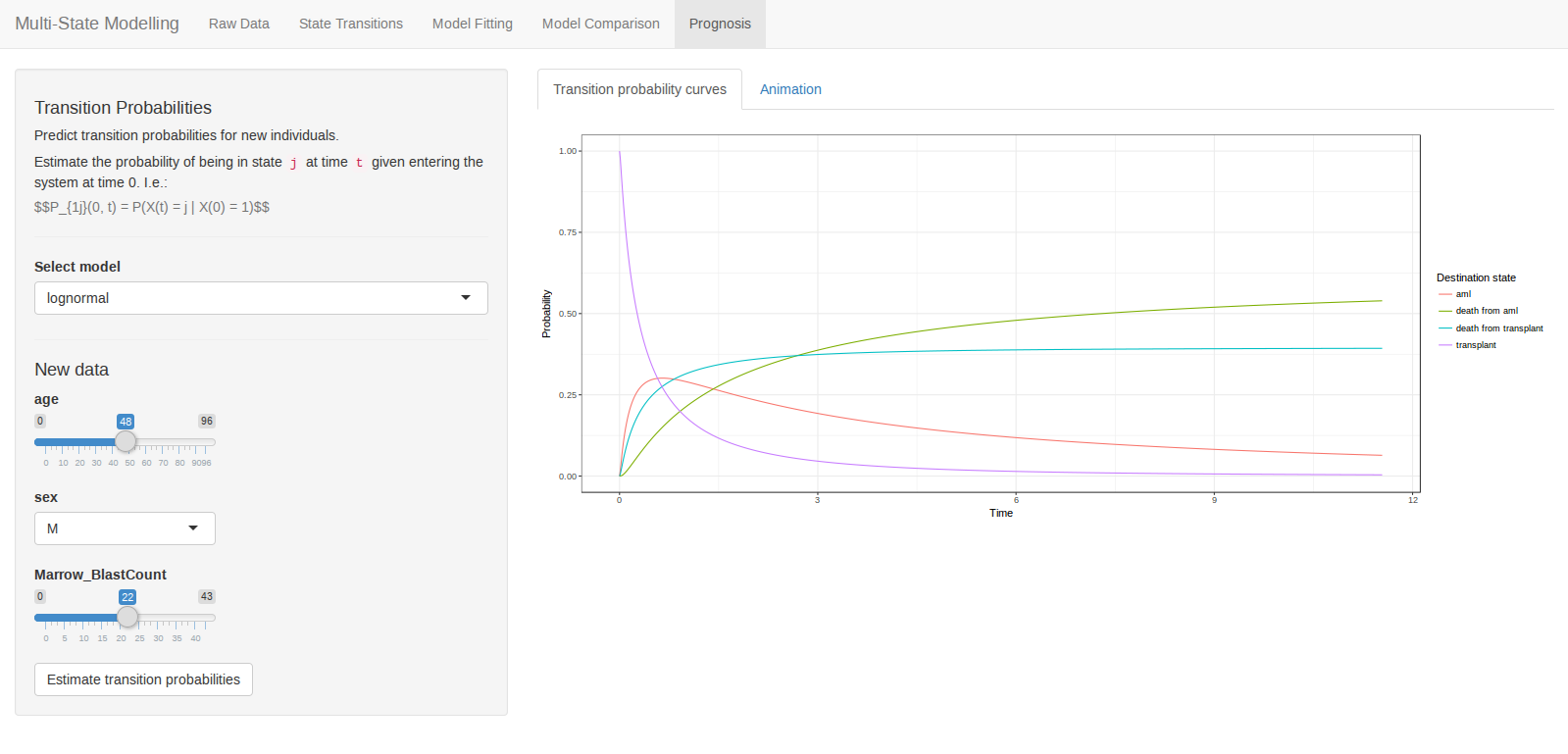
This talk discussed on an application of multi-state modelling to predict treatment pathways of a disease with heterogeneous disease management options, often involving multiple lines of active treatment.
Stuart E Lacy
Survival Analysis for Junior Researchers 2018, 2018.
Despite having notable advantages over established machine learning methods for time series analysis, reservoir computing methods, such as echo state networks (ESNs), have yet to be widely used for practical data mining applications. In this paper, we address this deficit with a case study that demonstrates how ESNs can be trained to predict disease labels when stimulated with movement data. Since there has been relatively little prior research into using ESNs for classification, we also consider a number of different approaches for realising input–output mappings. Our results show that ESNs can carry out effective classification and are competitive with existing approaches that have significantly longer training times, in addition to performing similarly with models employing conventional feature extraction strategies that require expert domain knowledge. This suggests that ESNs may prove beneficial in situations where predictive models must be trained rapidly and without the benefit of domain knowledge, for example on high-dimensional data produced by wearable medical technologies. This application area is emphasized with a case study of Parkinson’s disease patients who have been recorded by wearable sensors while performing basic movement tasks.
This work presented an interactive web application for building multi-state models of disease pathways. The app is flexible, allowing for both parametric and semi-parametric models, with transition-specific distributions. The presentation won the award for Best Presentation.
Stuart E Lacy, Stephanie J Lax
Survival Analysis for Junior Researchers 2017, 2017.
A survey of possible ways to evaluate survival models that are intended for prognostic, rather than inferential aims. The work was demonstrated on a clinically motivated data set of Follicular Lymphoma. This presentation won the Best in Session Award.
Stuart E Lacy, Stephanie J Lax
Survival Analysis for Junior Researchers 2016, 2016.
Ensembles are groups of classifiers which cooperate in order to reach a decision. Conventionally, the members of an ensemble are trained sequentially, and typically independently, and are not brought together until the final stages of ensemble generation. In this paper, we discuss the potential benefits of training classifiers together, so that they learn to interact at an early stage of their development. As a potential mechanism for achieving this, we consider the biological concept of mutualism, whereby cooperation emerges over the course of biological evolution. We also discuss potential mechanisms for implementing this approach within an evolutionary algorithm context
Michael Lones, Stuart E Lacy, Stephen L. Smith
Information and Processing in Cells and Tissues, 2015.