The last post showed that using a fully Bayesian multi-level model of the match outcomes helped Predictaball achieve a 58% overall prediction accuracy on the four European leagues, up 8% from last season. This post will describe the betting system I used to try and profit by identifying value bets in the offered odds.
Betting system
Before delving into the profit analysis I’ll firstly quickly summarise the staking model I used since I haven’t mentioned it anywhere before.
I haven’t any experience with this and so at first I tried a few naive schemes that bet unit stakes:
- Always betting on the outcome with the highest probability
- Betting on the outcome with the highest probability when this probability is greater than the bookies’ implied probability
- Betting on any outcome when the probability is greater than the bookies’ implied probability
Perhaps unsurprisingly, none of these made any profit on my test set of the 2015-2016 season. I then research ways of modifying the stake value itself and came across the well-known Kelly Criterion
$f^{*} = \frac{p(b+1)-1}{b}$
where $f^{*}$ is the fraction of bankroll to bet, $p$ is the estimated probability of the event and $b$ is the profit received from a unit bet if it paid out.
However, I found that this scheme resulted in me losing money and so I decided to get back into my comfort zone and implement a custom system. I formulated a model of the absolute stake to place $s$ as a function of the ratio between the predicted and implied probabilities of the outcome:
$$s = \beta{1} x{1} + \beta{2} x{2}$$
Where $x_{1}$ is the predicted probability and $x_{2}$ is the bookies’ implied probabilty. Fitting the coefficients with a standard Nelder-Mead optimisation resulted in a ratio of $\frac{\beta_{1}}{\beta_{2}} = -0.8$, i.e. if $x_{1} > 1.2x_{2}$ then a positive stake is given, with the value of the stake chosen by selecting an appropriate value for either $\beta_{1}$ or $\beta_{2}$. I chose a value that resulted in the maximum stake being £5, since I’m a cheapskate.
However, in hindsight I should have instead modelled bankroll ratio like the Kelly Criterion. Two main advantages of modelling stakes as a fraction of bank are that it allows for bigger profit when on a winning streak and it is impossible to go into the red provided appropriate limits are enforced when placing multiple bets simultaneously.
Note that the staking model doesn’t vary between leagues. This is an important point since the predicted probabilities are generated in the same way for each league, but the odds themselves may be determined differently for each league. I.e. the British-based bookies may have more knowledge of the Premier League and so can offer more accurate odds, or they may adjust odds to the bets being placed on them, so there may be more variance in popular markets.
I should also clarify that I didn’t actually place these bets as I considered this season a beta run of the betting system, but instead stored the odds and stakes each week so I can view what would have happened if I had placed them.
Betting profit
Overall
All that theoretical talk is all very well and good, but how much money would I have made if I had followed my automated tipping system? In short, blindly following the tips would have lost me money, but as we’ll see in a bit, a small amount of judgement and monitoring would have produced a nice steady profit.
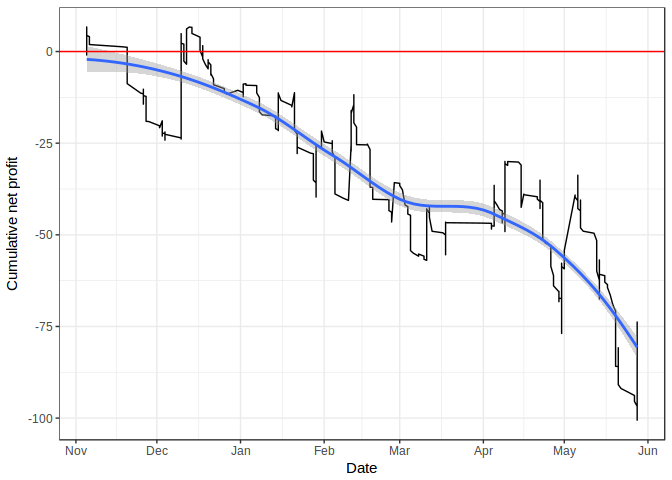
Across the entire season, the net profit was £-74.87 from 512 bets, with 81 (16%) having paid off. Obviously, this is poor, although we’ll identify why this is the case shortly and identify how to turn this around.
The plot below shows my cumulative profit over the season, showing a rather linear downwards trend.
Profit separated by league
To try and identify any small positives out of this we’ll try to diagnose what went wrong, starting with looking at profit broken down by league. Immediately from the table below, we can see that there is a large amount of inter-league variance, since the Premier League is in profit and the Bundesliga essentially breaks even. The Spanish and Italian leagues on the other hand don’t fare so well at all and are responsible for the majority of the loss.
What reason could there be for this large discrepancy? My pure speculation is that bookies adjust odds according to the number of bets being placed, and so in markets with a large number of bets being placed you’ll see more adjusted odds. I imagine that far more bets are being placed on the Premiership, but why would this result in profit for me? Again, I’d have to speculate that people here tend to vote for the favourite and so lengthen the odds on the underdog, thereby undervaluing them. This phenomena tends to happen whenever the England national team play, as they get massively overvalued, helping people like me make tidy profit when they lose to teams like Iceland. However, in markets such as Italy and Spain, I’d imagine the majority of people betting from the UK (where the bookies that I’ve used are based) on these markets are more informed and so don’t tend to upset the raw odds too much. I have no idea how to explain the Bundesliga however.
Interestingly, there seems to be an inverse relationship between the number of bets placed and the profit. This suggests that the optimal staking model (i.e. the premiership) has a high specificity since it identifies fewer poor value bets (false positives in this context).
| League | # bets | # won | Average stake | Profit |
|---|---|---|---|---|
| premiership | 115 | 26 | £0.88 | £24.44 |
| bundesliga1 | 126 | 27 | £1.04 | £-0.62 |
| seriea | 136 | 18 | £1.22 | £-36.43 |
| laliga | 135 | 10 | £0.92 | £-62.26 |
The plot below displays the profitability over the course of the season, separated by league. It shows that the overall profit of the Premiership is no fluke caused by a big winner on the last matchday, but a result of steady consistent wins throughout the season. Likewise profit on the Italian and Spanish leagues have been on a steady downwards trend all season long. The Bundesliga is a bit different in that for the first half of the season the net profit hovers around 0, before heading into the black as a result of 3 big wins, peaking at £20 profit, before dipping back to 0 by the end of the season. This is a point at which human intervention would pay off, as those 3 big wins could have been identified as anomalies and therefore deciding to stop placing bets on the Bundesliga before the winnings regressed to the mean.
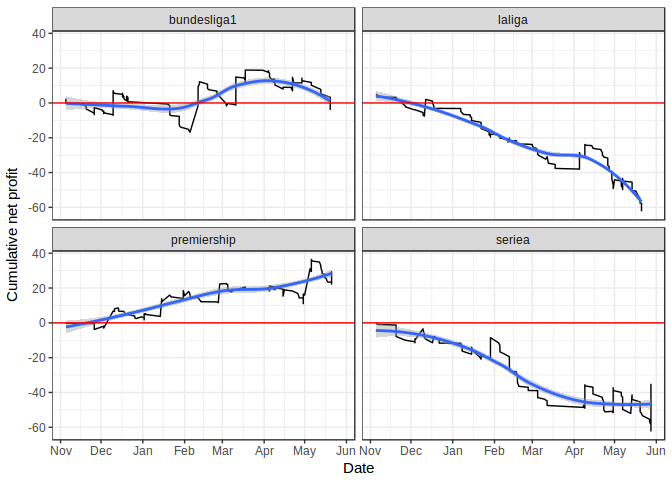
The main take home message from this section is that there is a large variation in profitability across the leagues, and any automated tipping system should be used with a grain of salt. Over this summer I’ll refine the model by taking the league into account, as well as incorporating human input to a greater degree. For example, by analysing historical data it may be evident that some leagues are more profitable than others, and so it would be easier to notice anomalies, such as when the Bundesliga was in profit in March, and stop betting at this point.
Relationship between predictability and profitability
Something that struck me during the above analysis was that there didn’t seem to be any relationship between the predictability and profitability of a league. While it is true that the Premiership achieved both the highest accuracy and largest profit, La Liga and Serie A had very high match prediction accuracy of 58% but both lost large amounts of money. The Bundesliga on the other hand only had 51% of outcomes correctly guessed, but broke even overall. Likewise, there doesn’t appear to be any patterns between the plots of accuracy and profitability broken down by league.
To me, this suggests that just because it may be hard to predict a sport, then it doesn’t mean you can’t make money on it. The converse is also true, while it is impressive being able to predict 58% of La Liga outcomes, it doesn’t count for a lot if the bookies can do it better.
Conclusions
From this analysis I’ve identified 3 main areas to work on over the summer to improve the model for next season.
I’ll firstly address the lack of accuracy at the start of the season, since it takes until December for the model to reach a steady state. Obviously part of this is due to the nature of an off-season where each team changes their squad and comes back at a different level to how they left off. The promotion of new teams adds an additional element of the unknown, since there is less historical data to estimate how they will fare in the new league. However, if I can capture these uncertainties in the data I feed my model, such as by using more team level attributes such as manager and squad changes, then hopefully my model can adapt more quickly.
Somewhat related to this, I’d like my model to adapt more quickly to teams that play well, such as the example with Leipzig. Currently the measure of a team’s strength is only calculated at the start of the season based on all available training data. If a team hasn’t been seen before then it is randomly assigned a strength. Instead, it would be useful to continuously update this, so for example Leipzig could enter the season with a randomly drawn strength value but this is updated to reflect their considerable abilit as they keep winning games. One standard way to do this is to use Elo scores. Elo scores could also help alleviate the uncertainty at the start of the season, by allowing the first $x$ games to count as “placement games” that update the Elo more strongly.
I’d going to spend more time on my admittedly rushed and naive betting modelling. Armed with the knowledge from this work, I’m going to look into stratifying my model by leagues, or other factors that could affect betting technique, thereby helping me to identify high value bets. Also, rather than outputting an absolute value to stake, the model should provide a ratio of my current bank, thereby allowing for exponential growth in the case as I had with the Premiership this season where I had consistent linear profit.